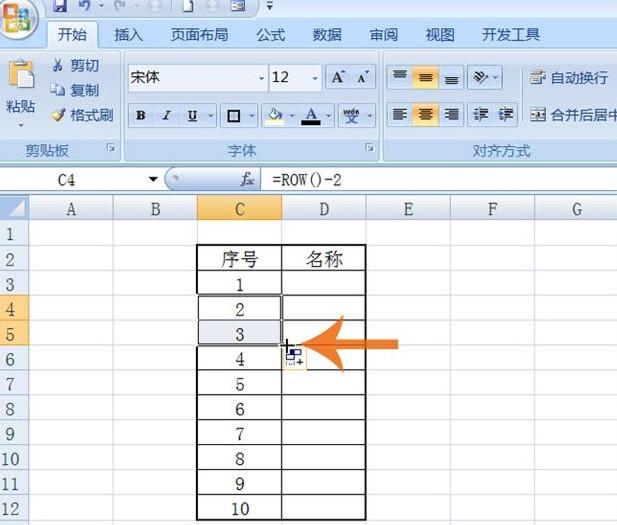
python操作excel主要用到xlrd和xlwt这两个库,xlrd是读excel,xlwt是写excel的库。
欢迎使用Markdown编辑器
你好! 这是你第一次使用 Markdown编辑器 所展示的欢迎页。如果你想学习如何使用Markdown编辑器, 可以仔细阅读这篇文章,了解一下Markdown的基本语法知识。
一、安装库
想要实现对excel文件的读写功能,需要安装一些库。下面三个库对excel进行读写操作必不可少。
1.xlwt:对xls等excel文件的写入
2.xlrd:对xls等excel文件的读取
3.openpyxl:对xlsm、xlsx等excel文件进行读写操作
4.xlutils结合xlrd可以达到修改excel文件目的
5.xlsxwriter可以写excel文件并加上图表
1.安装xlrd模块
到python官网下载http://pypi.python.org/pypi/xlrd模块安装,前提是已经安装了python 环境。
或者在cmd窗口 pip install xlrd
#查看版本
pip list
#安装指定版本
pip install xlrd == 1.2.0
#卸载
pip uninstall xlrd
2.安装xlwt模块
到python官网下载http://pypi.python.org/pypi/xlwt模块安装,前提是已经安装了python 环境。
或者在cmd窗口 pip install xlwt
2.安装openpyxl模块
或者在cmd窗口 pip install openpyxl
python_32">补充(多个python版本)
使用pip安装第三方模块
1.python2.x: cmd窗口输入python -m pip install 模块名
如 python -m pip install requests
2.python3.x: cmd窗口输入python3 -m pip install 模块名
如 python3 -m pip install requests
二、使用介绍
 excel表格如图所示" />
excel表格如图所示" />


1、常用单元格中的数据类型
0 - empty(空的) 1 - string(text) 2 - number 3 - date 4 - boolea 5 - error 6 - blank(空白表格)
2、导入模块
import xlrd
import xlwt
excel_47">3、Excel文件基础操作(读取excel数据)
#判断文件是否存在
print os.path.exists([路径/文件名]);
3.1 打开Excel文件读取数据(所有工作簿sheet)
data = xlrd.open_workbook(filename)
import xlrd;#对excel数据进行读取的库
workbook= xlrd.open_workbook(r'C:\Users\Administrator\Desktop\999.xls')
#文件名以及路径,如果路径或者文件名有中文给前面加一个r拜师原生字符。
#使用r就防止了\n的转义。
3.2获取工作簿sheet名称
print workbook.sheet_names()#输出sheet名[u'Sheet1', u'test', u'Sheet3']

#根据下标获取sheet名称
sheet_name=workbook.sheet_names()[0]
print sheet_name
#根据sheet索引获取sheet内容,同时获取sheet名称、行数nrows、列数ncols
sheet1 = workbook.sheet_by_index(0)
print sheet1.name,sheet1.nrows,sheet1.ncols
#根据sheet名称获取sheet内容,同时获取sheet名称、行数nrows、列数ncols
sheet1 = workbook.sheet_by_name('999')
print sheet1.name,sheet1.nrows,sheet1.ncols
3.3获取指定工作簿的行和列值
#根据sheet名称获取整行和整列的值
sheetData= workbook.sheet_by_name('test')
rows = sheetData.row_values(3)#第四行
cols = sheetData.col_values(0)#第一列
print rows
print cols
print workbook.sheet_names()

3.4获取指定单元格的内容
#sheetData= workbook.sheet_by_name('test')
print sheetData.cell(0,0).value#第一行第列
print sheetData.cell(9,0).value
print sheetData.cell_value(8,3)
print sheetData.row(7)[3].value
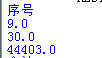
中文转码,在python文件首行加(#--coding:UTF-8-sig --)字符.首行首行注意。
如果不行的话,可加。encode(‘UTF-8’)进行转码例如:
sheet2.cell(0,0).value.encode(‘UTF-8’)
#获取单元格内容的数据类型
#(说明:ctype : 0 empty,1 string, 2 number, 3 date, 4 boolean, 5 error)
print sheetData.cell(3,0).ctype #4行1列: 2 为number类型
print sheetData.cell(3,1).ctype #4行2列: 3 为date类型
print sheetData.cell(3,2).ctype #4行3列: 1 为string类型

3.5获取单元内容为日期类型的方式
#获取单元内容为日期类型的方式
#使用xlrd的xldate_as_tuple处理为date格式,先判断表格的ctype=3时xlrd才能执行操作
先导入日期时间类型的库
from datetime import datetime,date
print sheetData.cell(9,1).ctype#第四行第三列的类型
print sheetData.cell(9,1).value#第四行第三列的值
#使用xlrd的xldate_as_tuple处理为date格式,先判断表格的ctype=3时xlrd才能执行操作
print xlrd.xldate_as_tuple(sheetData.cell_value(9,1),workbook.datemode)
date_value = xlrd.xldate_as_tuple(sheetData.cell_value(9,1),workbook.datemode)
print date(*date_value[:3])
print date(*date_value[:3]).strftime('%Y/%m/%d')

#如果是在脚本中需要获取并显示单元格内容为日期类型的,可以先做一个判断。
#判断ctype是否等于3,如果等于3,则用时间格式处理:
#if (sheetData.cell(row,col).ctype == 3):
#date_value = xlrd.xldate_as_tuple(sheetData.cell_value(row,col),book.datemode)
#date_tmp = date(*date_value[:3]).strftime(’%Y/%m/%d’)
if (sheetData.cell(8,1).ctype == 3):
date_value = xlrd.xldate_as_tuple(sheetData.cell_value(8,1),workbook.datemode)
date_tmp = date(*date_value[:3]).strftime('%Y.%m.%d')
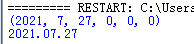
print date_value
print date_tmp
3.6获取合并单元格的内容
#获取合并单元格的内容
print sheetData.cell(11,0).value #第12行1,2,3列是合并单元格
print sheetData.cell(11,1).value #第12行1,2,3列是合并单元格
print sheetData.cell(11,2).value #第12行1,2,3列是合并单元格
print sheetData.cell(2,2).value #第3,4行的第3列是合并单元格
print sheetData.cell(3,2).value #第3,4行的第3列是合并单元格
print sheetData.cell(4,2).value #第5,6,7行的第3列是合并单元格
print sheetData.cell(5,2).value #第5,6,7行的第3列是合并单元格
print sheetData.cell(6,2).value #第5,6,7行的第3列是合并单元格
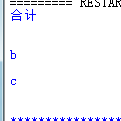
print sheetData.row_values(11)#输出第12行所有数据
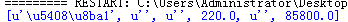
#在这里有个问题,合并单元格例如第12行1,2,3列只能获取
#第12行的第1列的值而第2,3列获取的内容为空,
#而第3,4行的第3列是合并单元格则只能获取
#第3行的第3列的值而第4列获取的内容为空,
#那么该如何处理呢
#可以利用merged_cells方法进行处理,处理的方法是只能获取合并单元格的
#第一个cell的行列索引,才能读到值,读错了就是空值。即合并行单元格读取
#行的第一个索引,合并列单元格读取列的第一个索引。
#这里,需要在读取文件的时候添加个参数,将formatting_info参数设置为True,
#默认是False,否则可能调用merged_cells方法获取到的是空值。
workbook = xlrd.open_workbook(r'C:\Users\Administrator\Desktop\999.xls',formatting_info=True)
sheetData = workbook.sheet_by_name('test')
print sheetData.merged_cells

#merged_cells返回的这四个参数的含义是:(row,row_range,col,col_range),
#merged_cells 返回的是一个列表,每一个元素是合并单元格的位置信息的数组,
#merged_cells返回的是一个数组,数组包含四个元素(起始行索引,结束行索引,起始列索引,结束列索引)
#其中[row,row_range)包括row,不包括row_range,col也是一样,下标从0开始。
#即(11, 12, 0, 3),的含义是:第12行,1到3列合并,
#(2, 4, 2, 3),的含义是:第3到4行合并,
#(4, 7, 2, 3),的含义是:第5到7行合并,
#(7, 11, 2, 3)的含义是:第8到11行合并,
#利用这个,可以分别获取合并的四个单元格的内容:
#[(11, 12, 0, 3), (2, 4, 2, 3), (4, 7, 2, 3), (7, 11, 2, 3)]
print sheetData.cell(11,0).value #(11, 12, 0, 3)第12行1,2,3列是合并单元格
print sheetData.cell(11,1).value #第12行1,2,3列是合并单元格
print sheetData.cell(11,2).value #第12行1,2,3列是合并单元格
print sheetData.cell(2,2).value #(2, 4, 2, 3)第3,4行的第3列是合并单元格
print sheetData.cell(3,2).value #第3,4行的第3列是合并单元格
print sheetData.cell(4,2).value #(4, 7, 2, 3)第5,6,7行的第3列是合并单元格
print sheetData.cell(5,2).value #第5,6,7行的第3列是合并单元格
print sheetData.cell(6,2).value #第5,6,7行的第3列是合并单元格
#发现规律了吗!是的,获取merge_cells返回的row和col低位的索引! 于是可以:
#merge = []
#for (rlow,rhigh,clow,chigh) in sheetData.merged_cells:
#merge.append([rlow,clow])
(merge函数,后续补充)
#[(11, 12, 0, 3), (2, 4, 2, 3), (4, 7, 2, 3), (7, 11, 2, 3)]
merge = []
for (rlow,rhigh,clow,chigh) in sheetData.merged_cells:
merge.append([rlow,clow])
print "000000000"
print "111111111"
merge
[[11, 0], [2,2], [4,2], [7,2]]
print "22222222222"
for index in merge:
print "33333333333"
print sheetData.cell_value(index[2],index[3])
3.7函数
#使用def函数注意缩进格式相同,否则会报错
我创建了一个test.py文件,并写入代码,保存。下面就先介绍main吧。
1.首先main 函数的意义
通俗的理解__name__ == ‘main’: test.py,相当于(name == ‘test’);
name__是内置变量,可用于反映一个包的结构层次。
name__是内置变量,可用于表示当前模块的名字。
当一个.py文件(模块)被直接运行时,若没有包结构,则__name__值为__main,即模块名为__main。
if name == ‘main’:的意思是:
当test.py文件被直接运行时,if name == ‘main’:之下的代码块将被运行;
当test.py文件以模块形式被导入时,if name == ‘main’:之下的代码块不被运行。
2.程序入口
一般来说,对编程语言而言,程序都必须要有一个入口,比如C,C++,以及完全面向对象的编程语言Java,C#等。如果你接触过这些语言,对于程序入口这个概念应该很好理解,C,C++都有一个main函数作为程序入口,也就是程序的运行会从main函数开始。同样,Java,C#则有一个包含Main方法的主类,作为程序入口。
而Python不同,它属于脚本语言,不像编译型语言那样先将程序编译成二进制再运行,而是动态的逐行解释运行。也就是从脚本第一行开始运行,没有统一的入口。
一个Python源码文件(.py)除了可以被直接运行外,还可以作为模块(也就是库),被其他.py文件导入。不管是直接运行还是被导入,.py文件的最顶层代码都会被运行(Python用缩进来区分代码层次),而当一个.py文件作为模块被导入时,我们可能不希望一部分代码被运行。
所以,实际上if name == 'main’相当于Python模拟的程序入口,Python本身并没有这么规定,这只是一种编码习惯。由于模块之间相互引用,不同模块可能有这样的定义,而程序入口只有一个。到底哪个程序入口被选中,这取决于__name__的值。
3.引用其他.py文件
from 【.py文件名称】 import 【变量】
from test import excel_name
if name == ‘main’:
try:
main()
except KeyboardInterrupt:
sys.stderr.write(“User interrupt me! 😉 Bye!\n”)
sys.exit(0)
4.Python程序的运行方式
Python的-m参数用于将一个模块或者包作为一个脚本运行,而__main__.py文件相当于是一个包的“入口程序“。
运行Python程序的两种方式
python xxx.py,直接运行xxx.py文件
python -m xxx.py,把xxx.py当做模块运行
假设我们有一个文件run.py,内容如下:
import sys
print(sys.path)
直接运行方式是把run.py文件所在的目录放到了sys.path属性中
模块方式运行是把你输入命令的目录(也就是当前工作路径),放到了 sys.path 属性中。
所以以模块方式运行会多出一行No module named run.py的错误。因为以模块方式运行时,Python先对run.py执行一遍 import,所以print(sys.path)被成功执行,然后Python才尝试运行run.py模块,但是在path变量中并没有run.py这个模块,所以报错。正确的运行方式,应该是python -m run。
5 main.py的作用
举个例子,假设我们有如下一个包package:
package
├── init.py
└── main.py
其中,文件__init__.py的内容
import sys
print(“init”)
print(sys.path)
其中,文件__main__.py的内容
import sys
print(“main”)
print(sys.path)
接下来,我们运行这个package,使用python -m package运行,输出结果:
init
[’’, …]
main
[’’, …]
使用python package运行,输出结果:
main
[‘package’, …]
总结:
1、 加上 -m 参数时,Python会把当前工作目录添加到 sys.path 中,而不加-m 时,Python会把脚本所在目录添加到 sys.path 中。
2、 加上 -m 参数时, Python 会先将模块或者包导入,然后再执行
3、 main.py 文件是一个包或者目录的入口程序。不管是用 python package 还是用 python -m package 运行时,main.py 文件总是被执行。
参考文章
https://blog.konghy.cn/2017/04/24/python-entry-program/.
3.8 定义数组
temp_sort = [(‘a’, 1, 1.5),
(‘b’, 2, 5.1),
(‘c’, 9, 4.3)]
excel_305">4、Excel文件基础操作(写入excel数据)
4.1创建Excel文件和sheeet工作簿
对excel进行写入操作时,需关闭excel文件,否则会报错IO
import xlwt;#对excel数据进行写入的库
writebook = xlwt.Workbook(encoding='utf-8')#生成excel文件并设置编码为utf8
sheet1 = writebook.add_sheet('Sheet1',cell_overwrite_ok=True)#创建第一个sheet 表单
excel_313">4.2对指定excel写入数据
#file.write(str)将字符串写入文件,返回的是写入的字符长度。
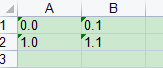
sheet1.write(0,0,"0.0")#第一行第一列
sheet1.write(0,1,"0.1")#第一行第二列
sheet1.write(1,0,"1.0")#第2行第一列
sheet1.write(1,1,"1.1")#第2行第二列
4.3保存文件
data = xlrd.open_workbook(filename)#文件名以及路径,如果路径或者文件名有中文给前面加一个r拜师原生字符,防止了\n转义。
#保存ExcelBook.save('path/文件名称.xls')
writebook.save(r'C:\Users\Administrator\Desktop\999.xls')
#关闭保存文件
writebook.close()
4.4自定义字体样式设置
style = xlwt.XFStyle() #初始化样式
font = xlwt.Font() #初始化字体
font.name = 'Times New Roman' #使用字体的名称
font.bold = True #字体加粗
font.underline = True #字体加下划线
font.italic = True #斜体字
style.font = font #设定样式使用的字体
sheet = writebook.add_sheet('Sheet1',cell_overwrite_ok=True)
sheet.write(1,0,"1.0")
sheet.write(1,1,"1.1")
sheet.write(0,0, '默认字体不带样式')#不带样式的表单内容
sheet.write(0,1, '黑体字下划线', style)#带样式的表单内容