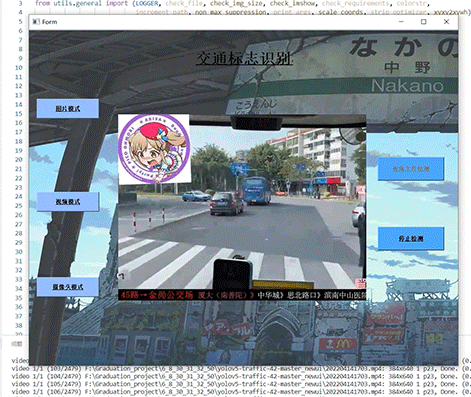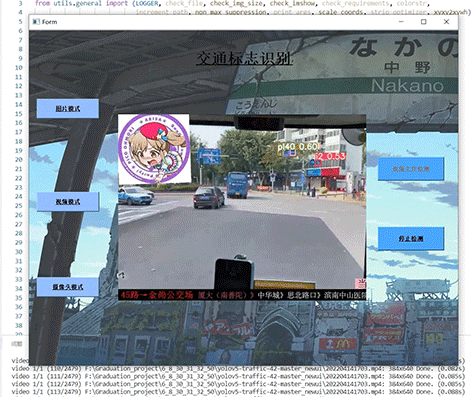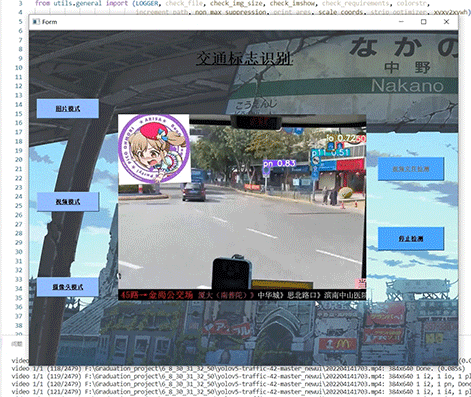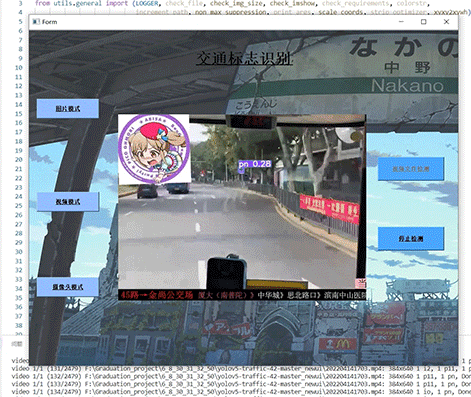
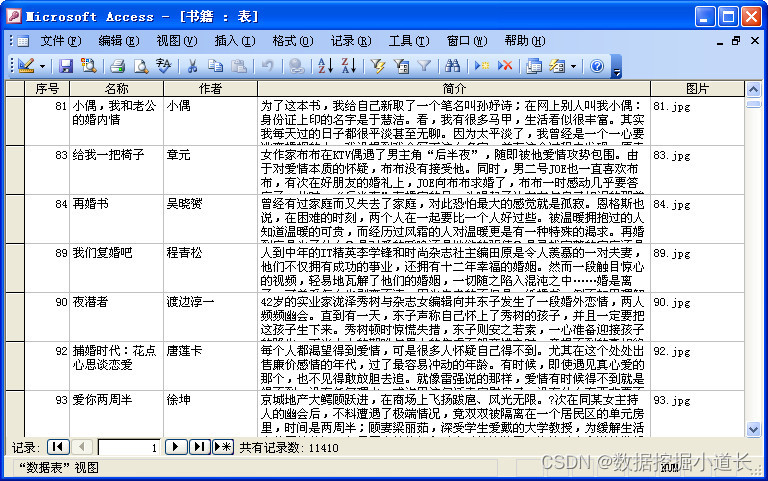
以学习实践VB.NET技术为主,对某一个书籍介绍网站进行了简单的内容采集,采集很成功(说明网站太简单没做什么防采集处理),采集的内容包含:序号、名称、作者、简介、图片。如下图:
这里的图片说的是书籍的封面小图,几乎每本书籍都下载了一个封面图片,通过这些封面可以得知,这些书籍几乎都是已出版的实体书目:
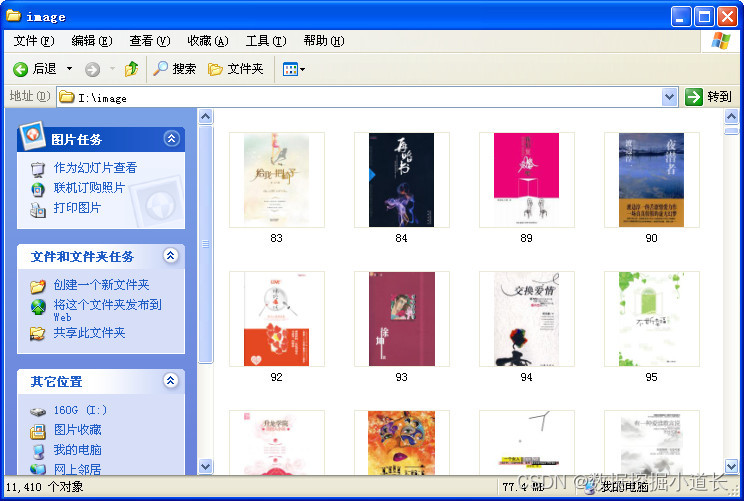
记录数也比较多,11410条,而这个数据的应用也可以说比较广泛,比如说可以做个手机应用每天推荐几本书等等。虽然没有下载地址什么的,但是完全可以根据书籍名称连接到各大书店或者书网进行购买或下载。
在这里贴出采集内容主在能够提高网站设计制作人员对网站防采集的处理,最好是图文混排,图片自动加水印等。
截图下方有显示“共有记录数”,截图包含了表的所有字段列。该数据提供ACCESS数据库文件(扩展名是MDB)以及EXCEL文件(扩展名是XLS)。