1 导入依赖
<!-- easyExcel -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>easyexcel</artifactId>
<version >3.2.1</version>
<exclusions>
<exclusion>
<artifactId>poi-ooxml-schemas</artifactId>
<groupId>org.apache.poi</groupId>
</exclusion>
</exclusions>
</dependency>2 写入操作
2.1 编写实体类
根据实体类,自动生成Excel表
java">package com.example.Easypojo;
import com.alibaba.excel.annotation.ExcelIgnore;
import com.alibaba.excel.annotation.ExcelProperty;
import lombok.EqualsAndHashCode;
import lombok.Getter;
import lombok.Setter;
import java.util.Date;
@Getter
@Setter
@EqualsAndHashCode
public class DemoData { // 写
@ExcelProperty("字符串标题")
private String string;
@ExcelProperty("日期标题")
private Date date;
@ExcelProperty("数字标题")
private Double doubleData;
/**
* 忽略这个字段
*/
@ExcelIgnore
private String ignore;
}2.2 测试
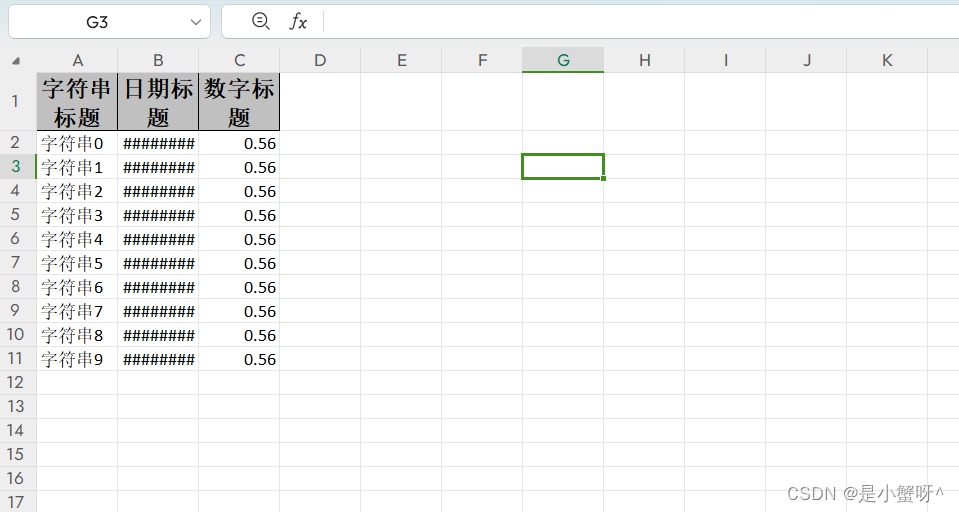
java">public class EasyExcelTest {
String PATH = "D:\\Idea-projects\\POI\\POI_projects";
private List<DemoData> data() {
List<DemoData> list = ListUtils.newArrayList();
for (int i = 0; i < 10; i++) {
DemoData data = new DemoData();
data.setString("字符串" + i);
data.setDate(new Date());
data.setDoubleData(0.56);
list.add(data);
}
return list;
}
// 根据list 写入excel
@Test
public void simpleWrite() {
// 注意 simpleWrite在数据量不大的情况下可以使用(5000以内,具体也要看实际情况),数据量大参照 重复多次写入
// 写法1 JDK8+
String fileName = PATH + "writeEasyTest.xlsx";
// 这里 需要指定写用哪个class去写,然后写到第一个sheet,名字为模板 然后文件流会自动关
// 参数:write(fileName, 格式类)
// sheet(表名)
// doWrite(写入的数据)
EasyExcel.write(fileName, DemoData.class).sheet("模板")
.doWrite(() -> {
// 分页查询数据
return data();
});
}
}
3 读取操作
3.1 首先需要一个监听器
java">package com.example.Easypojo;
import com.alibaba.excel.context.AnalysisContext;
import com.alibaba.excel.read.listener.ReadListener;
import com.alibaba.excel.util.ListUtils;
import com.alibaba.fastjson.JSON;
import lombok.extern.slf4j.Slf4j;
import java.util.List;
// 有个很重要的点 DemoDataListener 不能被spring管理,要每次读取excel都要new,然后里面用到spring可以构造方法传进去
@Slf4j
public class DemoDataListener implements ReadListener<DemoData> {
/**
* 每隔5条存储数据库,实际使用中可以100条,然后清理list ,方便内存回收
*/
private static final int BATCH_COUNT = 100;
/**
* 缓存的数据
*/
private List<DemoData> cachedDataList = ListUtils.newArrayListWithExpectedSize(BATCH_COUNT);
/**
* 假设这个是一个DAO,当然有业务逻辑这个也可以是一个service。当然如果不用存储这个对象没用。
*/
private DemoDAO demoDAO;
public DemoDataListener() {
// 这里是demo,所以随便new一个。实际使用如果到了spring,请使用下面的有参构造函数
demoDAO = new DemoDAO();
}
/**
* 如果使用了spring,请使用这个构造方法。每次创建Listener的时候需要把spring管理的类传进来
*
* @param demoDAO
*/
public DemoDataListener(DemoDAO demoDAO) {
this.demoDAO = demoDAO;
}
/**
* 这个每一条数据解析都会来调用
*
* @param data one row value. Is is same as {@link AnalysisContext#readRowHolder()}
* @param context
*/
// 读取数据会执行 invoke 方法
@Override
public void invoke(DemoData data, AnalysisContext context) {
System.out.println(JSON.toJSONString(data));
cachedDataList.add(data);
// 达到BATCH_COUNT了,需要去存储一次数据库,防止数据几万条数据在内存,容易OOM
if (cachedDataList.size() >= BATCH_COUNT) {
saveData();
// 存储完成清理 list
cachedDataList = ListUtils.newArrayListWithExpectedSize(BATCH_COUNT);
}
}
/**
* 所有数据解析完成了 都会来调用
*
* @param context
*/
@Override
public void doAfterAllAnalysed(AnalysisContext context) {
// 这里也要保存数据,确保最后遗留的数据也存储到数据库
saveData();
log.info("所有数据解析完成!");
}
/**
* 加上存储数据库
*/
private void saveData() {
log.info("{}条数据,开始存储数据库!", cachedDataList.size());
demoDAO.save(cachedDataList);
log.info("存储数据库成功!");
}
}上述代码中,根据需要导入相关的包即可
3.2 储存到数据库还需要使用DemoDAO
java">package com.example.Easypojo;
import java.util.List;
/**
* 假设这个是你的DAO存储。当然还要这个类让spring管理,当然你不用需要存储,也不需要这个类。
**/
public class DemoDAO {
public void save(List<DemoData> list) {
// 如果是mybatis,尽量别直接调用多次insert,自己写一个mapper里面新增一个方法batchInsert,所有数据一次性插入
}
}3.3 测试
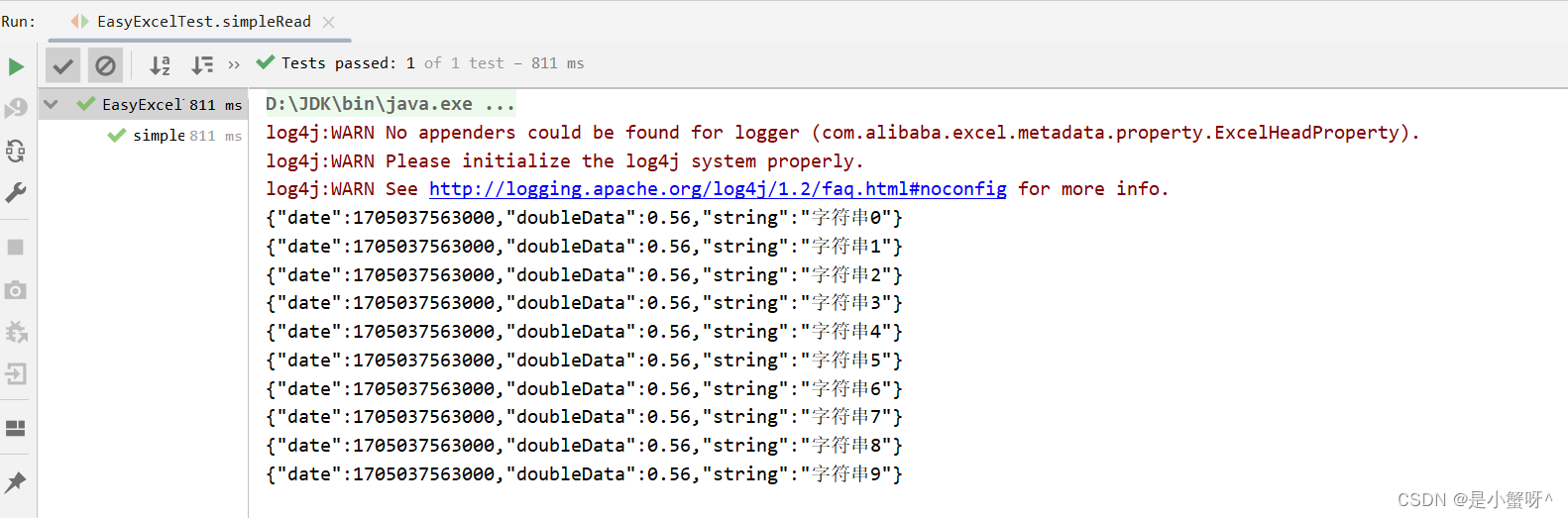
java"> @Test
public void simpleRead() {
// 写法1:JDK8+ ,不用额外写一个DemoDataListener
String fileName = PATH + "writeEasyTest.xlsx";
// 这里默认每次会读取100条数据 然后返回过来 直接调用使用数据就行
// 具体需要返回多少行可以在`PageReadListener`的构造函数设置
EasyExcel.read(fileName, DemoData.class, new DemoDataListener()).sheet().doRead();
}