单元格格式,根据数值的正负分配不同的颜色和↑ ↓
根据数值正负分配颜色
| 2 |
| -7 |
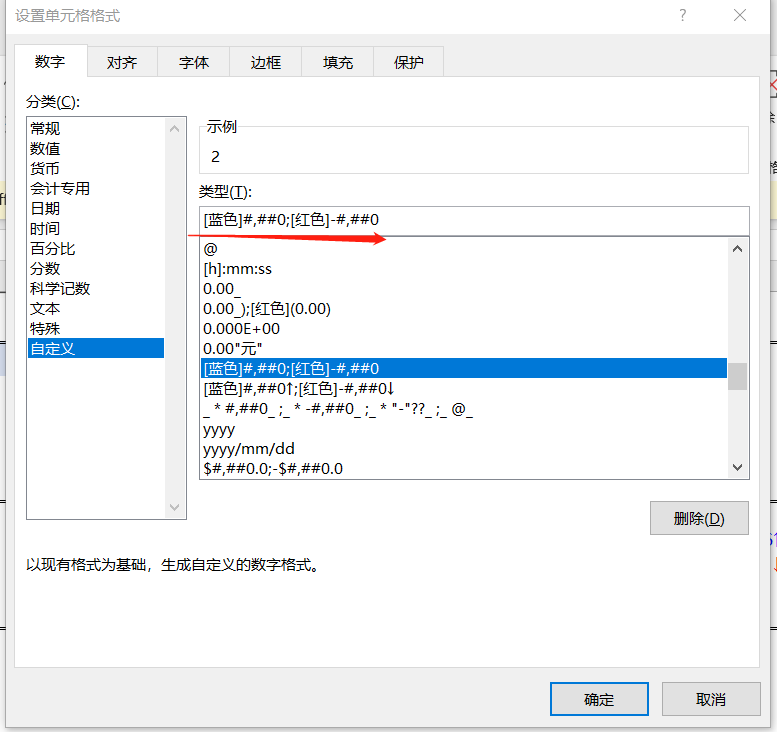
[蓝色]#,##0;[红色]-#,##0分配颜色的基础上,根据正负加↑和↓
| 2↑ |
| -7↓ |
其实就是在上面颜色的代码基础上加个 向上的符号↑,或向下的符号↓
[蓝色]#,##0↑;[红色]-#,##0↓只保留箭头,不要颜色
| 2↑ |
| -7↓ |
#,##0↑;#,##0↓保留占位符 #,##0 后面加个↑或↓ 。为什么要加这个占位符呢?这个占位符表示的就是-7和2,如果不写占位符,只写↑和↓,那么结果就不会有数字,就会变成下面这样只有↑和↓
| ↑ |
| ↓ |
IF函数
运算结果
公式

| =IF(SUM(AK122:AM122),SUM(AK122:AM122),"") |
IF函数是Excel中的逻辑函数,它根据指定的条件进行判断,并返回相应的结果。IF函数的语法如下:
IF(condition, value_if_true, value_if_false)
其中,参数的含义如下:
condition:要测试的条件或表达式。value_if_true:如果条件为真(即满足或不满足),则返回的值。value_if_false:如果条件为假(即不满足),则返回的值。
| =IF(SUM(AK122:AM122),SUM(AK122:AM122),"") |
如果 condition SUM(AK122:AM122) 只要不是0(那就是True),去取SUM(AK122:AM122)作为整个函数的输出值。
如果 condition SUM(AK122:AM122) 的值是0(那就是False),就取"" 一个空的字符串,作为整个函数的输出值。
防止没有数据的情况下,把流量统计成数字0
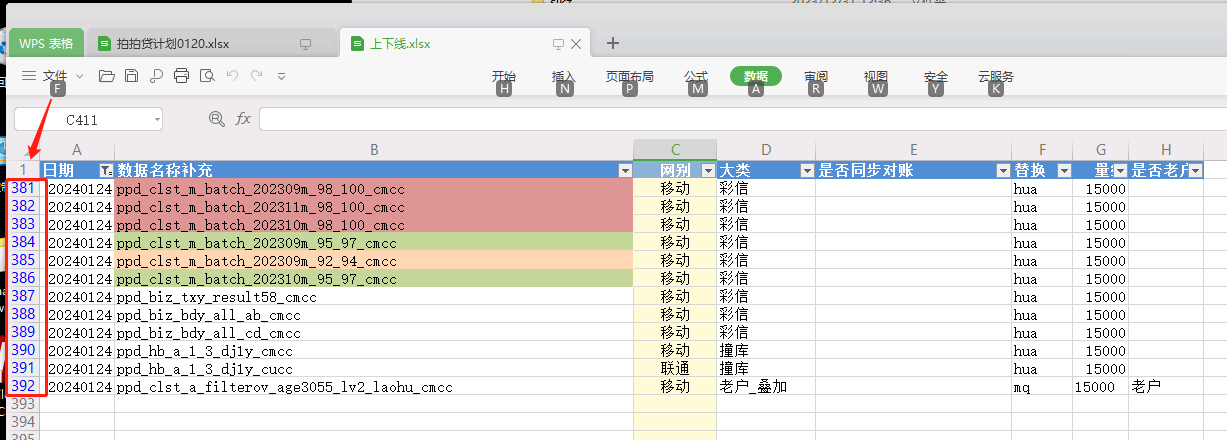
我想知道是什么样的操作可以让390行的Excel表只显示381行以后的数据(文件位置:远程桌面的上下线.xlsx)
Excel给一列中所有为空的行都填上“汇总”两个字我现在已经用Ctril+G选中了所有的空行,如何一次性填充所有的空行为“汇总”二字?
如果您已经使用 Ctrl + G 快捷键并通过“定位条件”选中了所有空行中的单元格,接下来可以一次性填充这些单元格为“汇总”二字。请按照以下步骤操作:
- 确保选中了所有空单元格:
- 如果您是通过“定位条件”选中了空值,那么所有空单元格应该已经被选中。
- 如果有些单元格没有被选中,您可以手动点击并扩展选择范围,或者使用
Ctrl+ 点击 来选中额外的单元格。
- 输入“汇总”二字:
- 直接在任意一个选中的空单元格中输入“汇总”。
- 使用
Ctrl + Enter填充所有选中单元格:- 在输入“汇总”后,不要直接按
Enter键,因为这样会只在当前单元格中填充内容。 - 相反,按下
Ctrl+Enter组合键。这将确保“汇总”二字被填充到所有选中的单元格中。
- 在输入“汇总”后,不要直接按
- 验证填充结果:
- 检查您的数据列,确保所有之前选中的空单元格现在都填充了“汇总”二字。
如果您按照这些步骤操作后,仍然发现有些单元格没有被填充,可能是因为有些单元格的格式问题或者它们并不是真正的空单元格(例如,它们可能包含空格或其他不可见字符)。在这种情况下,您可以再次使用“定位条件”来确保只选中了真正的空单元格,并重复上述填充步骤。
请注意,在进行此类批量操作时,务必先备份您的工作表,以防意外情况发生。
我在Excel表中遇到这个问题,A1写着2022-01-01,A1向下到A15都是空的,A16写着2022-01-02,A17-A27是空的,A28写着2022-01-03, A29-A40是空的。 后面还有上千行的数据都是类似情况,其中一行是有日期的,这一行以后十几行都是空的,我希望这十几行都填充上之前那一行?除了手动Ctrl+D填充,还有其他更便捷的方式吗?
🔺1、打开Excel文件后,选中要填充的空白单元格和周围的数据。
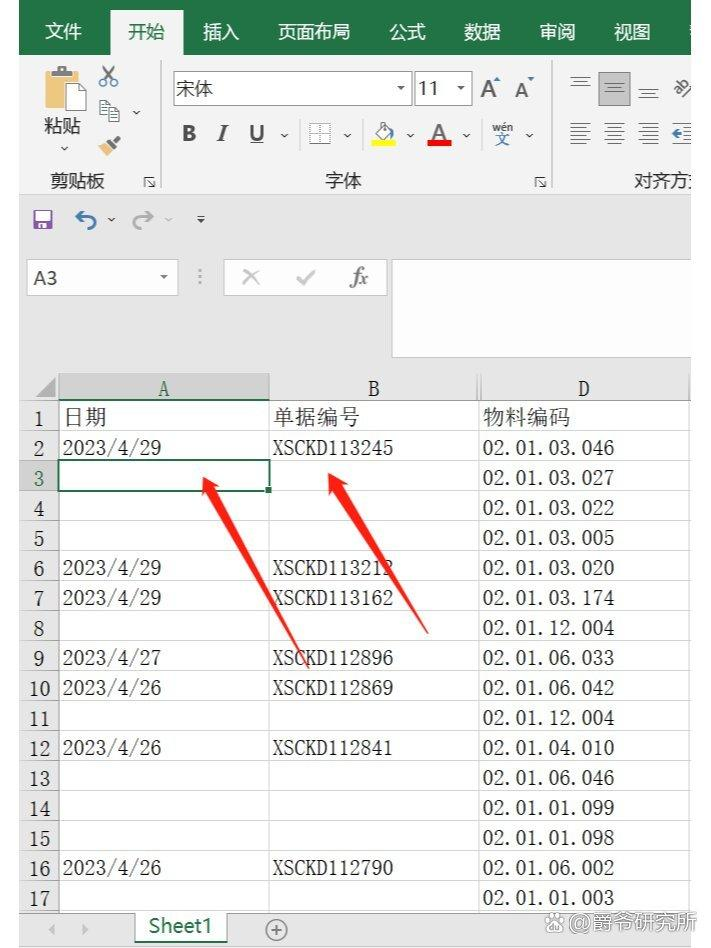
🔺2、按快捷键【Ctrl+G】或【F5】调出定位窗口,点击【定位条件】。
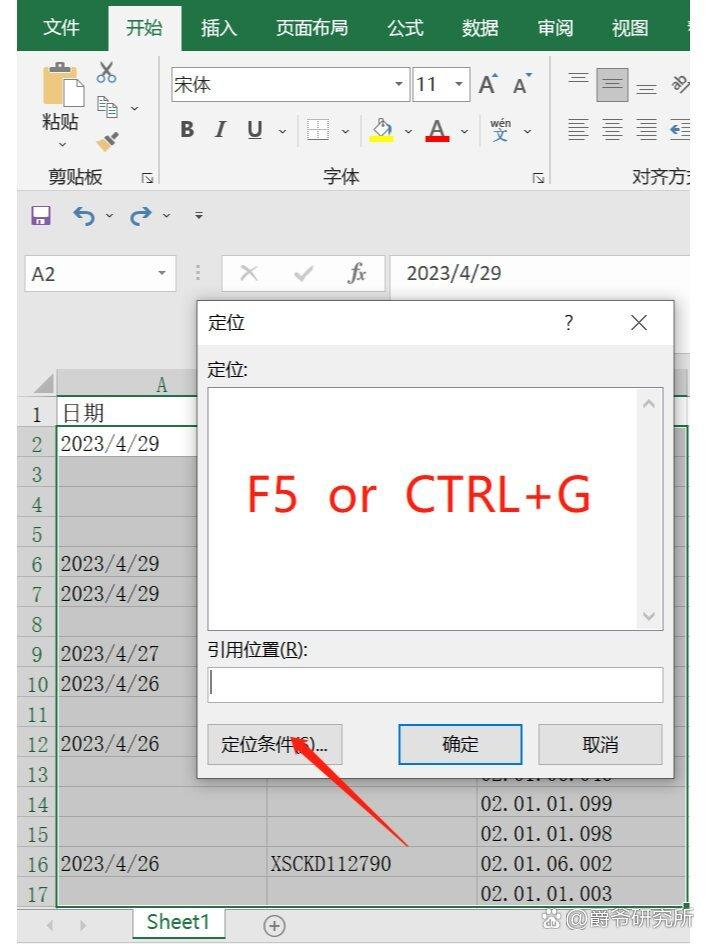
🔺3、勾选【空值(K)】,点击【确定】,将所有空白单元格全部选中,第一个空值背景色是白色,表示可以编辑。

🔺4、在第一个空值中输入【=】,点击上一行的单元格即【A2】,如图所示。

🔺5、按快捷键【Ctrl+Enter】,如图所示:已全部填充。
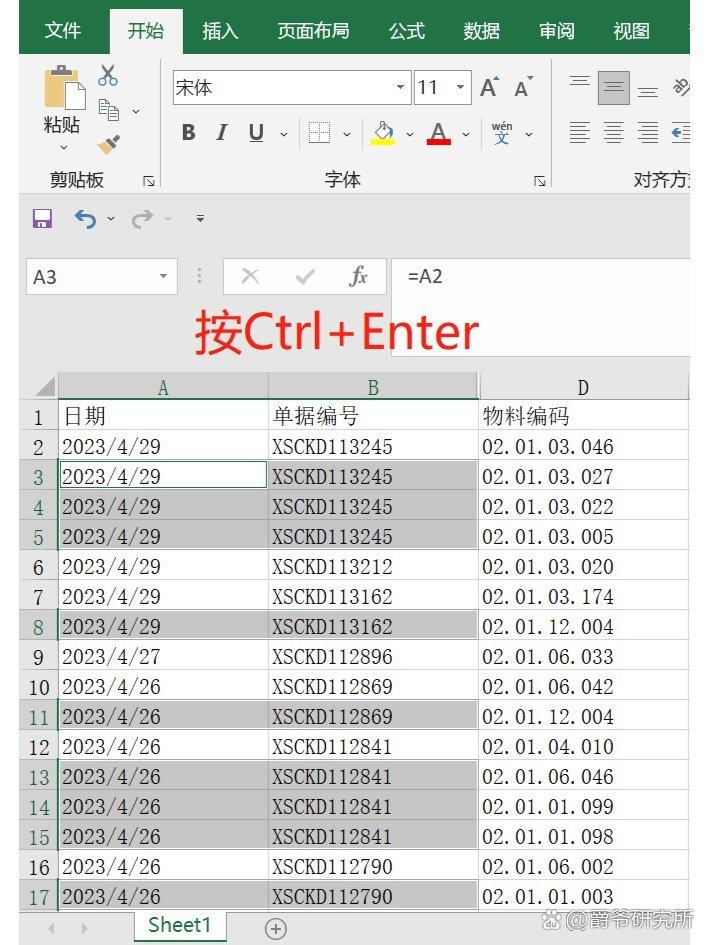
💥注意:选中空白表格时千万不要选中整列,否则整列都会执行填充功能,有可能导致excel卡住或闪退。
我们目前有一组数据,这组数据 每个数据 的权重我都已经设定好了,请问如何用Excel计算加权方差?
要在Excel中计算加权方差,你可以使用以下步骤:
-
准备数据:将你的数据列在Excel工作表的一列中(例如A列),并将相应的权重列在另一列中(例如B列)。
-
计算加权平均数:在空白单元格中输入以下公式来计算加权平均数:
=SUMPRODUCT(A1:An, B1:Bn) / SUM(B1:Bn)其中,A1:An是数据列的范围,B1:Bn是权重列的范围。SUMPRODUCT函数将每个数据值与对应的权重相乘,然后SUM函数将这些乘积的总和除以权重的总和来得到加权平均数。
-
计算加权方差:在另一个空白单元格中输入以下公式来计算加权方差:
=SUMPRODUCT((A1:An - 加权平均数)^2, B1:Bn) / SUM(B1:Bn)这里,你需要将
加权平均数替换为你在第2步中计算出的实际值。这个公式首先计算每个数据点与加权平均数的差的平方,然后将这些平方值与相应的权重相乘,最后将这些乘积的总和除以权重的总和来得到加权方差。
mstsc是英文Microsoft Terminal Services Client的缩写,中文意思是微软终端服务客户端。它是一个Windows系统内置的工具,用于远程连接到其他计算机或服务器。当你按下Win+R组合键并输入mstsc时,系统会打开远程桌面连接工具,让你能够连接到远程计算机。
手机中的DCIM是英文digital camera in memory的简写,中文意思是数字相机图像。这个文件夹通常用于存放数码相机拍摄的照片和视频,因此命名为DCIM。
常见的SQL有MySQL、Spark、Hive、Flink,请问什么情境下会使用哪一种数据库呢?
MySQL:
读写速度快
数据量GB到TB级别的数据用MySQL, 数据量数十TB或PB级别,一般用Hive
备注:不是只有Spark和Hive可以在集群上运行。MySQL 可以在集群上运行,也可以单机运行
Spark:
需要处理大规模数据集
特别是那些不能放入内存的数据集时
可以用于批处理、流处理、机器学习和图处理等。
高度优化,可以在集群上运行,支持多种数据源.就是你
Hive:
如果你们公司的数据已经存储在 Hadoop Distributed File System分布式文件系统(HDFS)中的数据。Hive 提供了一个类似 SQL 的查询语言(HQL)(Hive SQL),使得数据分析师可以更容易地查询和分析大数据。
Hive不适用于实时分析或低延迟场景,因为它的设计目的是为了批处理和大数据处理。如果你对实时性和低延迟有要求高且数据体量较大TB到PB级别,你应该用Flink。如果你对实时性和低延迟有要求高且数据体量是GB到TB级别,你应该用MySQL。
Hive真正的优势在于批处理。
什么是“批处理”?
批处理就是MapReduce,先分工,再汇总
批处理是一种数据处理方式,它将大量的数据分成小批次进行处理。每个批次的数据被单独处理,处理完成后将结果进行整合,得到最终的结果。在大数据处理中,批处理通常用于处理大规模数据集,因为这种方式可以充分利用计算资源,提高数据处理效率。
举个例子,假设我们要处理一个包含数百万条记录的大型数据集,需要进行数据分析、数据清洗和汇总等操作。如果我们使用传统的数据处理方式,可能会花费很长时间才能完成整个数据集的处理。而采用批处理方式,我们可以将整个数据集分成若干个小批次,每个批次的数据单独进行处理。这样,我们可以同时处理多个批次的数据,从而大大提高了数据处理效率。
在实际应用中,批处理通常用于数据仓库、ETL(提取、转换、加载)等场景。例如,在数据仓库中,数据从源系统经过ETL过程被加载到数据仓库中,这个过程可以采用批处理方式进行数据处理,以提高效率。
总之,批处理是一种高效的数据处理方式,尤其适用于大规模数据集的处理。通过将数据分成小批次进行处理,可以充分利用计算资源,提高数据处理效率。
Hive的性能较差,查询速度很慢,远远比MySQL、Spark、慢
Hive的速度之所以慢,是因为下面这些原因
一部分是因为Hive是在对HDFS上的这些硬盘中的文件进行汇总,需要进行频繁的磁盘读写操作。但是Spark呢使用了一种基于内存的计算模型。Spark将数据缓存在内存中,避免了频繁的磁盘读写操作,从而提高了计算速度。因此,对于需要处理大量数据、要求高性能的场景,例如实时数据分析、机器学习、流数据处理等,Spark可能是一个更好的选择。
实际上,Hive的性能问题更多是由于其计算模型和执行引擎的设计。
Hive使用了一种基于MapReduce的计算模型,这种模型在处理大数据时相对较慢,因为它需要在多个阶段进行数据分区、排序和聚合等操作。这些操作需要大量的计算资源和时间,导致Hive的查询速度相对较慢。
另外,Hive的执行引擎也存在一些性能瓶颈。Hive的查询计划需要通过一个中央协调器来执行,这会导致查询执行过程中的瓶颈和延迟。相比之下,一些其他的大数据处理工具(如Spark和Flink)采用了更为高效的计算模型和执行引擎,可以更快地处理数据。
Spark和Flink的执行引擎的优越性体现在下面几点
Spark的执行引擎称为Spark Engine,它采用了基于RDD的计算模型,可以进行弹性分布式计算。Spark Engine可以将多个操作转化为DAG图,按照最优的执行方式进行计算,从而减少了数据的读写、Shuffle等操作,提高了处理效率
Flink最大的特点是批流一体。在Flink中,所有的数据都被视为流进行处理,无论是批数据还是流数据,都可以在同一个Flink集群中进行处理。Flink的执行引擎称为Flink Engine,它是一个流处理和批处理的统一计算框架。Flink Engine支持有界和无界数据的流处理,可以对数据流进行实时处理和状态管理。与Spark相比,Flink在处理流数据时具有更好的实时性和低延迟性
从实时性上来说,Flink要优于Spark。
Flink:
需要实时数据处理和分析的应用。Flink 提供流处理stream和批处理batch,对于低延迟的场景非常适合。对实时性要求很高。
常用到Flink的行业和公司有下面这些。
推荐系统:电商领域的实时数据分析和推荐系统也是 Flink 的应用场景。例如,根据用户的实时行为和偏好,进行商品推荐。——实时处理和分析社交媒体数据和广告数据,进行用户分析和精准营销。
物联网(IoT)领域:物联网设备产生大量的实时数据,Flink 可以用于实时分析这些数据,进行设备监控、预警和智能调控等。
视频、游戏:
- 实时数据处理和分析:视频和游戏行业通常需要实时处理和分析大量的数据,例如用户行为、播放量、在线人数等。Flink提供了高吞吐、低延迟的流处理能力,可以满足这些实时数据处理和分析的需求。
- 实时反馈和推荐:在视频和游戏中,用户需要实时的反馈和推荐。Flink可以实时处理数据并给出反馈,例如推荐相关内容、提供挑战排名等,从而提高用户体验和留存率。
- 异常检测和实时监控:视频和游戏行业需要实时监控系统状态,及时发现异常情况并处理。Flink可以实时检测数据流中的异常,及时发出警报和处理,保证系统的稳定性和可用性。
- 流式广告投放:在视频和游戏中,广告投放是一个重要的收入来源。Flink的实时数据处理能力可以帮助实现流式广告投放,根据用户行为和偏好进行精准投放,提高广告效果和收益。
金融行业:金融市场数据是实时变化的,Flink 可以用于实时风险管理和欺诈检测。例如,实时监测交易行为和风险指标,进行实时风险管理和欺诈检测
物流行业:实时路况监测和配送优化是物流领域的重要需求,Flink 可以实时处理和分析路况数据,优化配送路线和提高配送效率。