环境
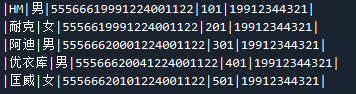
| HM | 男 | 55566619991224001122 | 101 | 19912344321 |
| 耐克 | 女 | 5556619991224001122 | 201 | 19912344321 |
| 阿迪 | 男 | 55566620001224001122 | 301 | 19912344321 |
| 优衣库 | 男 | 55566620041224001122 | 401 | 19912344321 |
| 匡威 | 女 | 55566620101224001122 | 501 | 19912344321 |

上表只是数据方便读者复制,上图才是我用的excel(read.xlsx),以下的程序都将以上图为准。
下面的程序,注意让Python源文件和Excel文件放到同一个目录即可。令read.xlsx有一个sheet名叫Sheet1,且内容如上图。
xlrd_17">使用xlrd读取
import xlrd#读取,这个库的行列索引都是从0开始的
workbook = xlrd.open_workbook(r'read.xlsx')
readSheet = workbook.sheet_by_name('Sheet1')
for row in range(2, readSheet.nrows):#nrows是最大索引加1,所以这里是每行都读取
#readSheet的索引从0开始的,因为第3排开始有数据,所以上面是2
col_2 = readSheet.cell(row, 1).value.strip()#姓名列是第二列,但索引从0开始,所以这里是1
col_3 = readSheet.cell(row, 2).value.strip()
col_4 = readSheet.cell(row, 3).value.strip()
col_6 = readSheet.cell(row, 5).value.strip()
col_9 = readSheet.cell(row, 8).value
print('|' + col_2 +'|' + col_3+'|' +col_4+'|' +col_6+'|' +str(int(col_9))+'|')
注意Excel里面,电话那一列不是字符串,是数值类型,所以readSheet.cell(row, 8).value是float类型。而其他的列,由于在Excel里都是字符串,所以代码返回值都是str类型,比如readSheet.cell(row, 1).value。
xlrd模块支持读取xls和xlsx两种格式。
openpyxl_38">使用openpyxl读取
openpyxl模块只支持读取xlsx格式。
按需读取
python">import openpyxl
#这个库的行列索引是从1开始的
writeBook_in = openpyxl.load_workbook('read.xlsx')
writeSheet_in = writeBook_in["Sheet1"]
for row in range(3,7):#从第3排开始,到第6排
col_2 = writeSheet_in.cell(row, 2).value.strip()#str类型
col_3 = writeSheet_in.cell(row, 3).value.strip()
col_4 = writeSheet_in.cell(row, 4).value.strip()
col_6 = writeSheet_in.cell(row, 6).value.strip()
col_9 = writeSheet_in.cell(row, 9).value#float类型,不能使用strip()
print('|' + col_2 +'|' + col_3+'|' +col_4+'|' +col_6+'|' +str(int(col_9))+'|')
无脑读取
python">import openpyxl
#这个库的行列索引是从1开始的
writeBook_in = openpyxl.load_workbook('read.xlsx')
writeSheet_in = writeBook_in["Sheet1"]
row_count = 0
col_count = 0
for row in writeSheet_in.rows:
row_count += 1
if row_count >= 3:
col_count = 0
for cell in row:
col_count += 1#此变量暂时没用上
print(cell.value, col_count, "\t", end="")#end="",令默认结束不是换行符
print('\n')
openpyxl_80">使用openpyxl新建
python">import openpyxl
workbook = openpyxl.Workbook()
sheet = workbook.active
sheet.title = 'Sheet1'
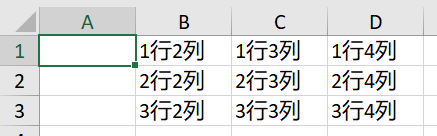
for i in range(1, 4):
for j in range(2, 5):
sheet.cell(row=i, column=j, value=str(i)+'行'+ str(j)+'列')
workbook.save('new.xlsx')#在源文件当前目录新建一个文件
openpyxl_94">使用openpyxl追加写入
我是用的是openpyxl模块,这个模块写入excel的好处是它不会改变原有excel的样式(最开始我用的是xlwt和xlutils,但是会改变原有样式)。

首先我们准备一个写入文件的模板(write_template.xlsx,其实这个文件就是read.xlsx的副本,只不过删除掉了数据部分),除了表头外,数据部分都是空着的。
python">import openpyxl #写入
#这个库的行列索引是从1开始的
writeBook_in = openpyxl.load_workbook('write_template.xlsx')
writeSheet_in = writeBook_in["Sheet1"]
writeRow_in = 3#数据行是从第3排开始的,且索引从1开始,所以这里是3
for row in range(3):#循环三次,所以到第5排
writeSheet_in.cell(writeRow_in, 2, '张三')
writeSheet_in.cell(writeRow_in, 3, '男')
writeSheet_in.cell(writeRow_in, 4, '55566619940909123456')
writeSheet_in.cell(writeRow_in, 6, '1-101')
writeSheet_in.cell(writeRow_in, 9, 15611112222)
writeRow_in += 1
writeBook_in.save("追加.xlsx")#在源文件当前目录新建一个文件
最后会生成一个追加.xlsx的新文件。效果如下:

注意,因为writeSheet_in.cell(writeRow_in, 9, 15611112222)写入的是int类型的变量,所以Excel的电话一列的数据类型也是数值类型。
openpyxl20_122">使用openpyxl追加写入2.0
其实原理就和上面一样了,直接把需要追加的excel作为写入模板,只需要注意开始写入的行即可。
python">import openpyxl #写入
#这个库的行列索引是从1开始的
writeBook_in = openpyxl.load_workbook('追加.xlsx')
writeSheet_in = writeBook_in["Sheet1"]
writeRow_in = 6#从第6排开始
for row in range(2):#循环两次,所以到第7排
writeSheet_in.cell(writeRow_in, 2, '李四')
writeSheet_in.cell(writeRow_in, 3, '女')
writeSheet_in.cell(writeRow_in, 4, '55566620121010123456')
writeSheet_in.cell(writeRow_in, 6, '1-101')
writeSheet_in.cell(writeRow_in, 9, 15611112222)
writeRow_in += 1
writeBook_in.save("追加第二版.xlsx")#在源文件当前目录新建一个文件

excel_147">实例:根据年龄分类excel的数据
现在想要把数据分为两种,一种是2003年以及之前出生的人,一种是2003以后出生的人,还有一种是身份证录入错误的人(会导致无法计算年龄,注意到耐克的身份证号是错误的,少了一位),并且把年龄一栏填上。
也就是说,要根据原有的文件read.xlsx,生成另外三个文件。因为需要生成新文件,所以也需要写入文件模板write_template.xlsx。
python">import datetime
import xlrd#读取,这个库的行列索引都是从0开始的
workbook = xlrd.open_workbook(r'read.xlsx')
readSheet = workbook.sheet_by_name('Sheet1')
import openpyxl #写入
#在范围内
writeBook_in = openpyxl.load_workbook('write_template.xlsx')
writeSheet_in = writeBook_in["Sheet1"]
#不在范围内
writeBook_out = openpyxl.load_workbook('write_template.xlsx')
writeSheet_out = writeBook_out["Sheet1"]
#身份证录入出错
writeBook_err = openpyxl.load_workbook('write_template.xlsx')
writeSheet_err = writeBook_err["Sheet1"]
writeRow_in = 3
writeRow_out = 3
writeRow_err = 3
def calculate_age(born):#参数类型datetime.datetime,该函数返回int类型的年龄值
today = datetime.datetime.now()
try:
birthday = born.replace(year=today.year)
except ValueError:
# raised when birth date is February 29
# and the current year is not a leap year
birthday = born.replace(year=today.year, day=born.day-1)
if birthday > today:
return today.year - born.year - 1
else:
return today.year - born.year
for row in range(2, readSheet.nrows):
#readSheet的索引从0开始的
col_2 = readSheet.cell(row, 1).value.strip()
col_3 = readSheet.cell(row, 2).value.strip()
col_4 = readSheet.cell(row, 3).value.strip()
col_6 = readSheet.cell(row, 5).value.strip()
col_9 = readSheet.cell(row, 8).value
dateErr = False
date_time = datetime.datetime.now()#获取当前时间作为默认时间
try:
#date_time这个变量是datetime.datetime类型
date_time = datetime.datetime.strptime(col_4[6:14],'%Y%m%d')
except ValueError:
print(col_2,col_4[6:14],'出错了')
dateErr = True
age = str(calculate_age(date_time))
if not dateErr:
check = int(col_4[6:10])#取出年龄
if check <= 2003:
writeSheet_in.cell(writeRow_in, 2, col_2)
writeSheet_in.cell(writeRow_in, 3, col_3)
writeSheet_in.cell(writeRow_in, 4, col_4)
writeSheet_in.cell(writeRow_in, 6, col_6)
writeSheet_in.cell(writeRow_in, 9, col_9)
writeSheet_in.cell(writeRow_in, 5, age)
writeRow_in += 1
else:
writeSheet_out.cell(writeRow_out, 2, col_2)
writeSheet_out.cell(writeRow_out, 3, col_3)
writeSheet_out.cell(writeRow_out, 4, col_4)
writeSheet_out.cell(writeRow_out, 6, col_6)
writeSheet_out.cell(writeRow_out, 9, col_9)
writeSheet_out.cell(writeRow_out, 5, age)
writeRow_out += 1
else:
writeSheet_err.cell(writeRow_err, 2, col_2)
writeSheet_err.cell(writeRow_err, 3, col_3)
writeSheet_err.cell(writeRow_err, 4, col_4)
writeSheet_err.cell(writeRow_err, 6, col_6)
writeSheet_err.cell(writeRow_err, 9, col_9)
writeRow_err += 1
writeBook_in.save("在范围内.xlsx")
writeBook_out.save("不在范围内.xlsx")
writeBook_err.save("出错了.xlsx")
下面三个图是三个新生成excel的内容。



其他
关于openpyxl模块,有的版本的openpyxl,在执行这句writeSheet_in.cell(writeRow_in, 2, '张三')时会出错,改成这样writeSheet_in.cell(None, writeRow_in, 2, '张三')就好了。(建议升级openpyxl来解决这个问题,不然还得修改代码)